Difference between count()
很不错的文章,果然还是看英文靠谱点。
The COUNT() function belongs to SQL’s aggregate functions. It counts the number of rows that satisfy the criteria defined in the parentheses. It does not return the rows themselves; it shows the number of rows that meet your criteria.
COUNT(*) vs COUNT(1)
The COUNT(*) function counts the total rows in the table, including the NULL values.
There’s a popular misconception that “1” in COUNT(1) means “count the values in the first column and return the number of rows.” From that misconception follows a second: that COUNT(1) is faster because it will count only the first column, while COUNT(*) will use the whole table to get to the same result.
So what does the value in the parenthesis of COUNT() mean? It’s the value that the COUNT() function will assign to every row in the table. The function will then count how many times the asterisk (*) or (1) or (-13) has been assigned. Of course, it will be assigned a number of times that’s equal to the number of rows in the table. In other words, COUNT(1) assigns the value from the parentheses (number 1, in this case) to every row in the table, then the same function counts how many times the value in the parenthesis (1, in our case) has been assigned; naturally, this will always be equal to the number of rows in the table. The parentheses can contain any value; the only thing that won’t work will be leaving the parentheses empty.
Since it doesn’t matter which value you put in the parentheses, it follows that COUNT(*) and COUNT(1) are precisely the same. They are precisely the same because the value in the COUNT() parentheses serves only to tell the query what it will count.
If these statements are precisely the same, then there’s no difference in the performance. Don’t let the asterisk (*) make you think it has the same use as in SELECT * statement. No, COUNT(*) will not go through the whole table before returning the number of rows, making itself slower than COUNT(1).
So, in the end, who wins in this dramatic COUNT(*) vs COUNT(1) battle? Nobody – it’s a draw; they’re exactly the same. However, I’d recommend using COUNT(*), as it’s much more commonly seen. It’s also less confusing, naturally leading other SQL users to understand that the function will count all the numbers in the table, including the NULL values.
COUNT(*) vs COUNT(column name)
As you’ve already learned, COUNT(*) will count all the rows in the table, including NULL values. On the other hand, COUNT(column name) will count all the rows in the specified column while excluding NULL values.
Always remember: COUNT(column name) will only count rows where the given column is NOT NULL.
COUNT() allows us to use expressions as well as column names as the argument. Do you know how to find the number of the orders above €1 000 using only the COUNT() function? Here’s how:
|
|
Instead of putting conditions at the end of the query and filtering after the COUNT() function does its job, we can use the CASE statement. That’s what I’ve done in the above query. It’s used like an IF-THEN-ELSE statement. CASE is followed by the condition, which is defined by the statements WHEN and THEN. There can also be an ELSE statement, but it’s unnecessary in this case – I’m only interested in counting the number of values, not in the values themselves. Every CASE statement ends with the END statement.
The COUNT() statement above reads as follows:
- Find all the values in the column
order_priceabove 1 000. - Assign the value 1 (you can assign any value you want) to these values.
- Assign NULL to rows with prices below 1 000.
- Count the number of assigned 1s.
- Show the result in the column
significant_orders.
Here’s the result:
| significant_orders |
|---|
| 5 |
COUNT(column name) vs COUNT (DISTINCT column_name)
You can probably imagine what the difference between those two COUNT() function versions is. COUNT(column_name) will include duplicate values when counting. In contrast, COUNT (DISTINCT column_name) will count only distinct (unique) rows in the defined column.
XML CDATA
所有 XML 文档中的文本均会被解析器解析。
只有 CDATA 区段(CDATA section)中的文本会被解析器忽略。
术语 CDATA 指的是不应由 XML 解析器进行解析的文本数据(Unparsed Character Data)。
在 XML 元素中,"<" 和 “&” 是非法的。
“<” 会产生错误,因为解析器会把该字符解释为新元素的开始。
“&” 也会产生错误,因为解析器会把该字符解释为字符实体的开始。
某些文本,比如 JavaScript 代码,包含大量 “<” 或 “&” 字符。为了避免错误,可以将脚本代码定义为 CDATA。
CDATA 部分中的所有内容都会被解析器忽略。
CDATA 部分由 “” 结束:
|
|
在上面的例子中,解析器会忽略 CDATA 部分中的所有内容。
关于 CDATA 部分的注释:
CDATA 部分不能包含字符串 “]]>"。也不允许嵌套的 CDATA 部分。
标记 CDATA 部分结尾的 “]]>” 不能包含空格或折行。
JOIN
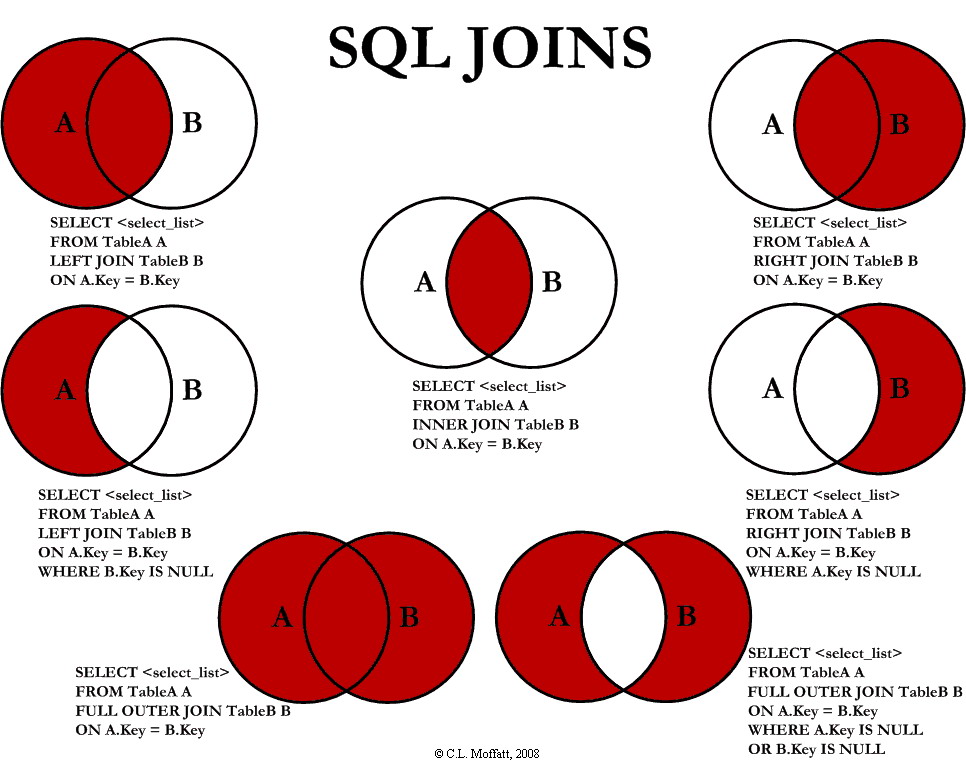
SQL Join statement is used to combine data or rows from two or more tables based on a common field between them.
INNER JOIN
The INNER JOIN keyword selects all rows from both the tables as long as the condition is satisfied.
Note: We can also write JOIN instead of INNER JOIN. JOIN is same as INNER JOIN.
LEFT JOIN
This join returns all the rows of the table on the left side of the join and matches rows for the table on the right side of the join. For the rows for which there is no matching row on the right side, the result-set will contain null. LEFT JOIN is also known as LEFT OUTER JOIN.
RIGHT JOIN
RIGHT JOIN is similar to LEFT JOIN. This join returns all the rows of the table on the right side of the join and matching rows for the table on the left side of the join. For the rows for which there is no matching row on the left side, the result-set will contain null. RIGHT JOIN is also known as RIGHT OUTER JOIN.
FULL JOIN
FULL JOIN creates the result-set by combining results of both LEFT JOIN and RIGHT JOIN. The result-set will contain all the rows from both tables. For the rows for which there is no matching, the result-set will contain NULL values.
OVER and PARTITION BY
Grouping Data using the OVER and PARTITION BY Functions
笔记:
The OVER and PARTITION BY functions are both functions used to portion a results set according to specified criteria.
We have 10 records in the student table and we want to display the name, id, and gender for all of the students, and in addition we also want to display the total number of students that belong to each gender, the average age of the students of each gender and the sum of the values in the total_score column for each gender.
As you can see, the first three columns (shown in black) contain individual values for each record, while the last three columns (shown in red) contain aggregated values grouped by the gender column. For example, in the Average_Age column, the first five rows display the average age and the total score of all the records where gender is Female.
Our result set contains aggregated results joined with non-aggregated columns.
Now let’s extend this and add ‘id’ and ‘name’ (the non-aggregated columns in the SELECT statement) and see if we can get our desired result.
|
|
When you run the above query, you will see an error:
The error says that the id column of the student table is invalid within the SELECT statement since we are using GROUP BY clause in the query.
This means that we will have to apply an aggregate function on the id column or we will have to use it in the GROUP BY clause. In short, this scheme doesn’t solve our problem.
Solution Using JOIN Statement
One solution to this would be to make use of the JOIN statement to join the columns with aggregated results to columns containing non-aggregated results.
To do so, you need a sub-query that retrieves gender, Total_Students, Average_Age and the Total_Score of the students grouped by gender. These results can then be joined to the results obtained from the sub-query with the outer SELECT statement. This will be applied to the gender column of the sub-query containing the aggregated result and the gender column of the student table. The outer SELECT statement would include non-aggregated columns i.e. ‘id’ and ‘name’, as below.
|
|
The above query will give you the desired result but is not the optimal solution. We had to use a JOIN statement and a sub-query which increases the complexity of the script. This is not an elegant or efficient solution.
A better approach is to use the OVER and PARTITION BY clauses in conjunction.
Solution Using OVER and PARTITION BY
To use the OVER and PARTITION BY clauses, you simply need to specify the column that you want to partition your aggregated results by. This is best explained with the use of an example.
Let’s have a look at achieving our result using OVER and PARTITION BY.
|
|
This is a much more efficient result. In the first line of the script the id, name and gender columns are retrieved. These columns do not contain any aggregated results.
Next, for the columns that contain aggregated results, we simply specify the aggregated function, followed by the OVER clause and then within the parenthesis we specify the PARTITION BY clause followed by the name of the column that we want our results to be partitioned as shown below.
SELECT - OVER Clause (Transact-SQL)
StackOverflow – Difference Between PARTITION BY and GROUP BY
Oracle Functions
DECODE FUNCTION
Oracle / PLSQL: DECODE Function
ROW_NUMBER()
What’s The Difference Between Oracle ROWNUM vs Oracle ROW_NUMBER?
笔记:
What Happens If You Use Oracle ROWNUM and ORDER BY?
The data has been ordered by the last_name value, but the ROWNUM is not in order.
This is because the ROWNUM happens just before the ORDER BY.
This is because the Oracle ROWNUM is applied after the WHERE clause.